여러 가지 로그들을 확인하고 리눅스 명령어(grep, awk, sed, argus-client)를 이용해 원하는 데이터를 추출하는 방법에 대해 실습해보았다.
로그(Log)
컴퓨터, 네트워크 등에서 접속하거나 어떤 일이 발생하였을 때 등 사용한 기록을 남기는 것을 말한다.
어떠한 문제가 발생했을 때 로그 파일을 분석하면 원인이나 시스템 전반의 상태 등 중요한 정보들을 알아낼 수 있다.
디지털 포렌식에서도 정보 수집을 위해서 로그 분석을 진행한다.
웹서버에는 누가 접근했는지 기록하는 access.log와 에러가 났을 때 기록하는 error.log가 있다.
또한 주기적으로 로그를 백업하여 access.log.1, access.log.2와 같이 넘버링을 해서 압축된다.
로그의 5하 원칙
로그는 유의미한 내용을 가져야 하기 때문에 대부분 5하 원칙을 지켜서 작성된다.
누가 / 언제 / 어디서 / 무엇을 / 어떻게
다음은 /apache/access.log의 로그 내용 중 하나이다.
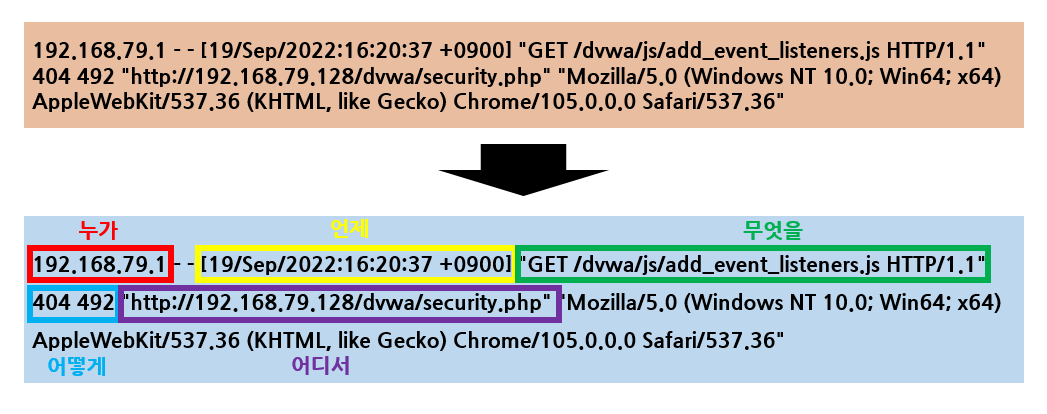
그냥 봤을 때에는 이해하기 힘들었으나 5하원칙을 대입하였을 때 어떤 내용인지 이해가 될 것이다.
192.168.79.1이 2022년 9월 19일 16:20:37에 /dvwa/security.php에서
GET 요청을 492 크기로 보냈는데 404 에러가 발생했다.
이렇듯 로그를 이해하기 위해서 5하원칙을 적용하면 쉽게 이해할 수 있다. 그러나 로그마다 각각의 규격이 다를 수 있다는 점은 알아두자.
로그 분석
5하원칙을 이용해 로그를 읽을 수 있다고 하여도 우리가 항상 불편하게 하나하나 이해할 수는 없는 노릇이다.
우리는 로그 분석을 통해 필요한 정보만을 추출하고 재조합하여 양질의 데이터를 만들 수 있다.
리눅스의 이점
로그 분석에 필요한 많은 오픈소스가 존재하며 무료로 이용할 수 있다.
CLI환경으로 작업하여 대용량 로그 분석에 용이하다.
파이프라인(|)을 이용해 분석 툴을 유기적으로 조합할 수 있다.
쉘 스크립트를 통한 자동화된 분석이 가능하다.
다수의 파일을 반복적으로 작업할 수 있다.
분석에 필요한 명령어
데이터 출력
| 명령어 | 옵션 | 설명 |
| cat [ file ] | 띄어쓰기로 파일 연결 출력 가능 | file 내용 전체 출력 |
| head [file] | -n [ line ] : line 수만큼 출력 -c [ byte ] : 원하는 바이트만큼 출력 |
file 앞에서부터 10줄 출력 |
| tail [file] | -n [ line ] : line 수 만큼 출력, -n +[ line ] : 앞에서 line 수를 제외한 나머지 출력 -c [ byte ] : byte 만큼 출력 -f : 파일 변화를 실시간으로 확인 |
file 뒤에서부터 10줄 출력 |
| less [file] | g : 처번째 라인으로 이동 G : 마지막 라인으로 이동 f, spcae : 다음 페이지 보기 enter : 한 줄씩 보기 /, ? : 이후/이전 검색어 찾기 q : 나가기 |
file 을 한번에 보여지는 만큼 출력하고 페이지 이동이 가능 |
정렬 / 중복 제거
| 명령어 | 옵션 | 설명 |
| sort [file] | -n : 숫자를 취급하여 정렬에 사용 -r : 내림차순으로 정렬 -f : 정렬 시 대소문자 무시 -u : 중복되는 라인 출력 안함 |
라인을 기준에 따라 정렬한다. |
| uniq [file] | -c : 같은 라인 빈도 수 표시 -u : 중복이 없는 라인만 출력 |
연속된 라인 중 중복된 라인을 제거한다. |
데이터 추출
| 명령어 | 옵션 | 설명 |
| grep '[패턴]' [file] | -c : 일치하는 행의 수 출력 -v : 일치하지 않는 행만 출력 -E : 정규표현식으로 탐색 -F : 문자열로 탐색 |
패턴에 맞는 내용을 가진 라인을 출력한다. |
| sed -n -e '[command]' [file] | -n : 패턴 버퍼의 내용을 출력안함 (내용 추출 시에만 사용) -e '[command']' : 연속으로 사용시 [command] 'n, mp' : n째줄부터 m줄까지 출력($는 끝까지) '/문자열/p' : 문자열 포함한 라인 출력 '/문자열/d' : 문자열을 포함한 라인을 지우고 출력 's/[old]/[new]/gi' : 문자열 치환(정규표현식 가능) - g는 문서전체, i는 대소문자 구분 없음 |
파일의 내용을 훼손하지 않고 치환하거나 라인을 원하는 만큼 추출 가능 특수문자를 문자열로 사용하려면 escape를 진행해야한다. |
awk 명령어
awk [옵션] '패턴 {액션}' [file] : 라인이 패턴에 맞으면 액션을 수행함.
기본적으로 공백을 기준으로 문자열을 나누며 순서마다 $1, $2로 표현한다. ($0은 전체 라인)
패턴으로 문자열, 정규식, 매칭 연산(~, !~)이 사용된다.
다양한 사용방법이 존재해 예제를 준비하였다.
awk '{print "result:"$1}' // 라인마다 첫 분기를 포멧에 맞게 출력한다.
awk -F "|" // |을 구분자로 사용한다.
awk '/정규식/ {print}' // 정규식에 맞으면 해당 라인을 출력한다.
awk -v 변수=값 // awk에서 변수로 지정해 사용
awk '$1 =="abc"{print $0}' // $1이 abc이면 해당 라인을 출력한다.
awk '$4~/^A+/ {print $3 $6}' // $4가 정규식에 맞으면 $3 $6을 출력한다.
awk -F "|" '$2~/^Res/ && $4~"A" {print $3" > "$6}'
// $2가 Res로 시작하고 $4가 A이면 라인에서 $3과 $6사이에 " > "를 추가하여 출력한다.이 밖에 여러 조건문과 함수가 존재하지만 다루지 않는다.
ra 명령어 [ Argus-client 설치 필요 ]
openArgus라는 네트워크 활동 감시 기술에서 제공되는 데이터 추출 명령어로 .arg 로그 파일을 분석할 때 사용한다.
BPF(Berkely Packet Filter) 이용 : 사람의 언어와 매우 유사하여 사용이 쉽다.
ra -nzr [file] // .arg 파일을 argus 포맷으로 출력
ra -nzr [file] -s [출력할 항목] - "[조건]" // 조건에 부합하는 라인을 원하는 항목만 출력
ra -nzr [file] -s saddr, daddr // 소스 주소와 목적지 주소만 출력
ra -nzr [file] - "ip proto TCP" // 프로토콜이 TCP 인것만 출력
ra -nzr [file] -s saddr, sport - "dst port (80 or 443)" // 목적지 포트가 80이나 443인 라인의 소스ip와 port를 출력| -s 옵션 항목 | stime : 로그가 기록된 시간 saddr : 소스 ip sport : 소스 port daddr : 목적지 ip dport : 목적지 port proto : 프로토콜 |
|
| - 옵션 조건 | src host [ip] src net [ip] src port [ip] |
소스의 IP주소, 네트워크 주소, 포트 |
| dst host [ip] dst net [ip] dst port [ip] |
목적지의 IP주소, 네트워크 주소, 포트 | |
| ip proto [protocol] | 프로토콜 | |
더 많은 내용은 아래 주소에서 확인할 수 있다.
https://manpages.debian.org/testing/argus-client/ra.1.en.html
ra(1) — argus-client — Debian testing — Debian Manpages
ra - read argus(8) data. SYNOPSIS¶ ra [raoptions] [-- filter-expression] DESCRIPTION¶ Ra reads argus(8) data from either stdin, an argus-file, or from a remote data source, which can either be an argus-server, or a netflow data server, filters the record
manpages.debian.org
쉘 스크립트 반복문 활용
대표적인 반복문 for, while을 이용하면 bash에서도 다양한 기능을 응용할 수 있다.
로그 분석 실습에서 사용할 반복문의 기본 형태는 다음과 같다.
for i in 1 2 3 4 5; do echo $i; done
cat [file] | while read i; do echo $i; done
로그 분석 실습
실습 파일은 해킹을 당한 가상의 시나리오를 바탕으로 진행한다.
파일은 Argus IDS의 로그파일 1_merged_total.arg, DNS 로그 파일 2_dns.log로 진행하였다.
1. DNS 로그 파일을 분석해서 IP와 도메인으로 구성된 파일로 만들기
우선 파일의 구조를 알아보기 위해 tail 명령어를 이용해 열어보았다.
tail 2_dns.log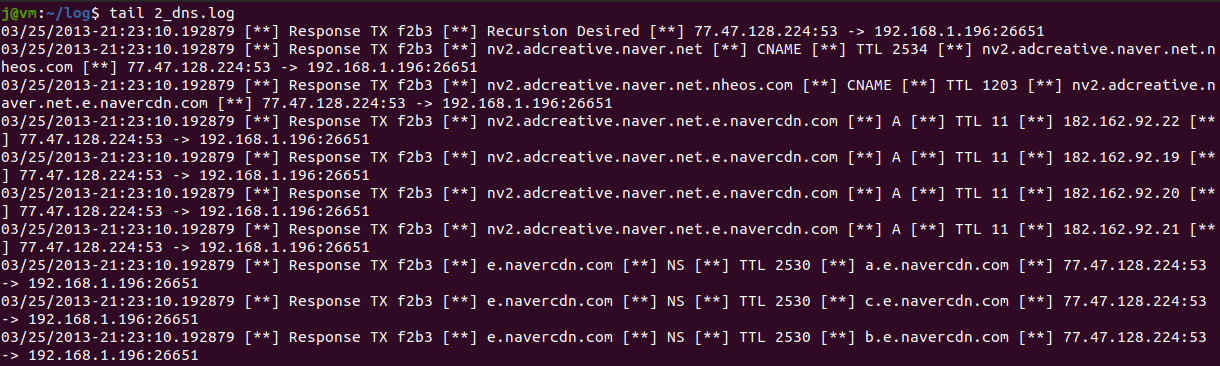
dns 로그 파일은 확인하여 알아낼 수 있는 것은 다음과 같다
1. [**]를 구분자로 사용하고 있다.
2. 2번째에서 DNS 패킷이 Query인지 Response인지 알 수 있다.
3. 3번째에는 Domain Name이 위치한다.
4. 4번째에는 DNS 레코드가 위치한다. Domain Name에 맞는 IP를 응답하는 레코드는 'A', 'AAAA' 이다.
5. 6번째에 Domain Name에 맞는 IP가 위치한다.
우리는 알아낸 정보를 이용해서 Domain Name와 IP가 매칭 된 내용의 파일을 만들어야 한다.
우선 파일의 내용을 정리하여 데이터를 조작하기 쉬운 상태로 만들어보자.
cat 2_dns.log | sed -e 's/\[\*\*\]/|/g -e 's/ //g' | tail명령어의 내용은 다음과 같다.
2_dns.log 전체 내용 출력 > sed를 이용해 [**] 구분자를 |로 변경하고 공백 제거 > 확인을 위해 tail로 일부만 출력
sed 명령어로 치환할 때는 정규식이 사용 가능하기 때문에 기능을 하는 특수문자 앞에 \를 두어 escape 처리를 해야 한다.
Escape 처리 : 일련의 기능을 하는 특수문자를 문자로 입력할 경우 기능을 하지 않도록 특수문자 앞에 \를 붙인다.

결과가 조금은 깔끔해졌다.
이제 DNS 결과를 응답하는 라인만 추출하기 위해 다음과 같은 명령어를 사용한다.
이때 위의 명령어를 사용한 결과를 저장한 것이 아니기 때문에 이어서 작성한다.
cat 2_dns.log | sed -e 's/\[\*\*\]/|/g -e 's/ //g' | \
awk -F "|" '$2~/Response/ && $4~/^A+/{print}' | tail추가된 명령어의 내용은 다음과 같다.
awk 명령어의 구분자를 "|"로 사용하고 두 번째에 Response가 들어가고 4번째에 A로 시작하는 라인을 출력

Domain Name으로 IP를 응답하는 라인 내용만 출력된다.
이제 여기서 3번째에 있는 Domain Name과 6번째에 있는 IP만을 출력하게 하면 된다.
cat 2_dns.log | sed -e 's/\[\*\*\]/|/g -e 's/ //g' | \
awk -F "|" '$2~/Response/ && $4~/^A+/{print $3 $6}' | sort -u | tail기존 awk 명령어에 print를 수정하여 3번째와 6번째를 출력 > sort의 -u를 이용해 정렬한 뒤 중복 제거

결과가 잘 출력되나 너무 붙어있으니 사이에 한 칸을 띄운 뒤 파일로 저장한다.
cat 2_dns.log | sed -e 's/\[\*\*\]/|/g -e 's/ //g' | \
awk -F "|" '$2~/Response/ && $4~/^A+/{print $3" "$6}' | sort -u > dns.lookup
아주 만족스럽게 저장이 되었다!
2. Argus 로그 파일을 분석해서 접속량 상위 30개의 Dst IP, Port와 접속한 Src IP 추출
로그 분석은 로그 파일을 열어 포맷을 확인하는 것부터 시작한다.
argus 로그파일은 argus-client 모듈의 ra 명령어를 사용해 열 수 있다.
ra -nzr 1_merged_total.arg | head
로그 파일이 구조화되어 있다는 걸 느낄 수 있다.
ra의 bpf를 이용한 편리한 명령어를 이용해 tcp를 사용한 라인만을 추출해보자
ra -nzr 1_merged_total.arg - "ip proto TCP" | head
tcp를 사용한 라인만 잘 출력된다.
이제 소스와 목적지 주소, 포트만 출력되도록 명령어를 사용해보자
ra -nzr 1_merged_total.arg -s saddr dport daddr - "ip proto TCP" | head
명령어를 굳이 설명하지 않아도 읽어보면 대충 알 수 있을 정도로 쉽게 구성된다.
이 데이터를 가지고 빈도수를 구해볼 것이다. 주의할 점은 첫 줄에 속성 타이틀은 빼고 구해야 한다는 것이다.
ra -nzr 1_merged_total.arg -s saddr dport daddr - "ip proto TCP" | tail +2 | sort | uniq -c | sort -rn | head
or // 둘 중 하나 사용
ra -nzr 1_merged_total.arg -s saddr dport daddr - "ip proto TCP" | sed -n '2,$p' | sort | uniq -c | sort -rn | headra의 명령어 결과를 첫 줄 빼고 정렬 > 중복 제거 후 빈도수 기입 > 빈도수 내림차순으로 정렬

결과가 거의 추려졌다.
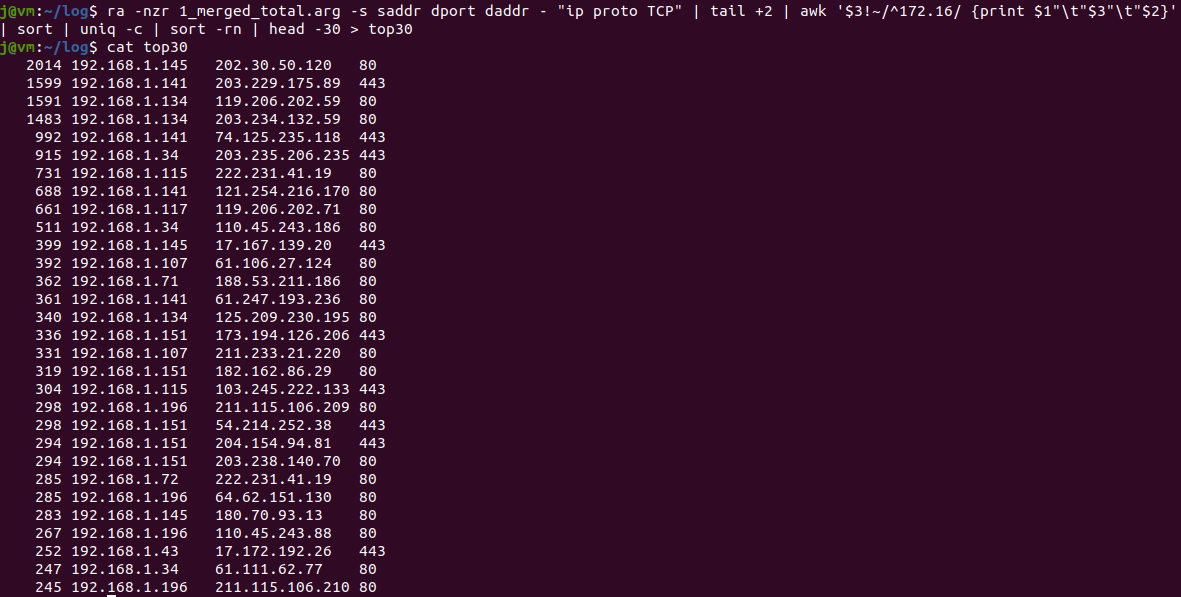
마지막으로 목적지 IP가 사설인 경우(172.16.*.*)를 제외한 뒤 내용의 순서를 [ 빈도, src ip, dst ip, dst port ] 순으로 배치한다.
또한 상위 30개를 출력한 뒤 저장하자.
ra -nzr 1_merged_total.arg -s saddr dport daddr - "ip proto TCP" | tail +2 | awk '$3!~/^172.16/ {print $1"\t"$3"\t"$2}' | sort | uniq -c | sort -rn | head -30 > top30awk 문을 이용해 조건을 부여하고 문자열의 순서를 조정 후 파일로 저장하였다.
3. 위 두 분석 파일을 합쳐 2번 파일에 도메인 추가하기
top30파일과 dns.lookup 파일을 이용하여 top30에서 접속한 IP의 도메인을 추가한 top30_domain파일을 생성할 것이다.
쉘 반복문을 이용하여 다음과 같이 구성할 수 있다.
cat top30 | while read line
do
dip = $(echo $line | awk '{print $3}'
echo $line $(cat dns.lookup | awk -v ip=$dip '$2~ip {print $1}')
done > top30_domain
//한줄
cat top30 | while read line; do dip=$(echo $line | awk '{print $3}'); echo $line $(cat dns.lookup | awk -v ip=$dip '$2~ip {print $1}'); done > top30_domain1. while문을 이용하여 top30 파일의 각 라인을 불러온다.
2. 라인의 3번째(목적지 IP)를 dip 변수에 저장한다.
3. dns.lookup 파일을 읽어 2번째(목적지 주소)와 dip가 일치하면 1번째(Domain)를 출력한다.
4. 3번을 line과 함께 붙여서 출력한다.
5. 출력 결과를 top30_domain에 저장한다.

결과를 보면 top30의 결과 옆에 도메인 주소를 보여주면서 어디에 접속했는지 알 수 있도록 구성하였다.
도메인 중 의심 가는 사이트가 있다면 bling.in이다.
.in은 인도 사이트의 도메인 국가 코드이기 때문이다.
로그가 있다면 이러한 방식으로 의심점을 찾아낼 수 있다.
우리는 로그 파일을 이용해서 필요한 내용을 추출하고 데이터를 정제하여 원하는 목적에 맞는 파일을 작성하였다.
'보안 이론 > 시스템 보안' 카테고리의 다른 글
| Metasploit을 이용한 시스템 취약점 점검 실습 (0) | 2022.09.26 |
|---|---|
| 리눅스의 파일 시스템과 디렉터리 별 특징 (0) | 2022.09.24 |

